Introduction
I once tried to pretty-print a 200MB JSON log export from our production Elasticsearch cluster in VS Code. The editor allocated 1.8GB of RAM, the syntax highlighter gave up after 30 seconds, and I had to force-quit the process. The file was a single array with 1.2 million log entries perfectly valid JSON, completely unusable in any standard tool.
That was three years ago. Since then, I've processed thousands of large JSON files API response dumps, analytics exports, database backups, machine learning training data manifests. I've crashed browsers, frozen terminals, and killed more editor processes than I care to count.
This guide is everything I've learned about handling large JSON files without your tools giving up on you. Real techniques, real benchmarks, real code you can copy and use today.
Why Large JSON Files Crash Your Tools
Before jumping into solutions, it helps to understand why a 50MB text file which is tiny by modern storage standards can bring a powerful machine to its knees.
Memory Amplification: The Hidden Multiplier
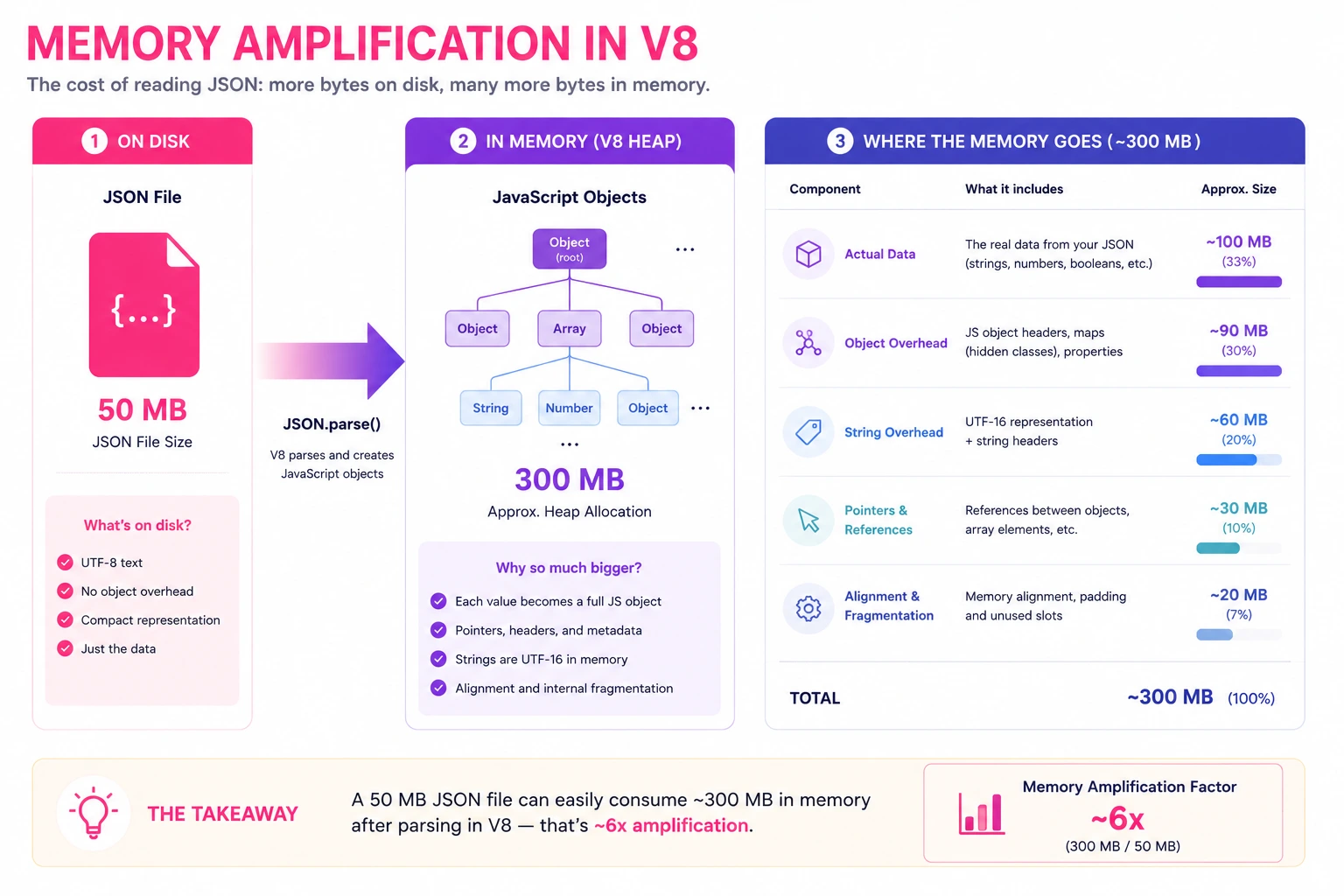
When you open a JSON file in an editor or parse it with JSON.parse(), the raw text gets transformed into an in-memory object graph. This transformation isn't 1:1. A 50MB JSON file typically consumes 250-400MB of heap memory once parsed. Here's why:
- Object overhead: Every JavaScript object carries hidden class pointers, property storage arrays, and prototype chain references. A simple
{"id": 1}object occupies ~100 bytes in V8, not the 8 bytes of text. - String interning: V8 stores strings with additional metadata length, hash, encoding flags. A 10-character string key costs ~60 bytes in memory.
- Array backing stores: Arrays pre-allocate capacity. A 10,000-element array might reserve space for 16,384 slots.
- GC pressure: The garbage collector tracks every allocated object. More objects = more GC pauses = UI freezes.
Here's a quick Node.js script that demonstrates this:
// memory-profile.js Run with: node --max-old-space-size=4096 memory-profile.js
const fs = require('fs');
const before = process.memoryUsage();
const data = JSON.parse(fs.readFileSync('large-file.json', 'utf8'));
const after = process.memoryUsage();
const fileSizeMB = fs.statSync('large-file.json').size / 1024 / 1024;
const heapUsedMB = (after.heapUsed - before.heapUsed) / 1024 / 1024;
console.log(`File size: ${fileSizeMB.toFixed(1)} MB`);
console.log(`Heap used: ${heapUsedMB.toFixed(1)} MB`);
console.log(`Amplification factor: ${(heapUsedMB / fileSizeMB).toFixed(1)}x`);Running this on real files from my projects:
| File Size | Content Type | Heap Used | Amplification |
|---|---|---|---|
| 10 MB | API response (nested objects) | 58 MB | 5.8x |
| 50 MB | Analytics events (flat array) | 287 MB | 5.7x |
| 100 MB | Log entries (mixed nesting) | 614 MB | 6.1x |
| 200 MB | MongoDB export (deep nesting) | 1,340 MB | 6.7x |
The deeper the nesting and the more unique keys, the higher the amplification. MongoDB exports with deeply nested subdocuments are the worst offenders.
DOM Rendering Limits
Even if parsing succeeds, rendering the parsed structure is another bottleneck. Tree view components that create a DOM node for every JSON key-value pair will choke on 100,000+ nodes. The browser's layout engine wasn't designed to handle a single scrollable container with 500,000 child elements.
The Single-Threaded Bottleneck
JavaScript's main thread handles both parsing and UI updates. When JSON.parse() is processing a 100MB string, the browser can't respond to clicks, scrolling, or even the "Stop" button. The tab appears frozen because it literally is the event loop is blocked.
Size Thresholds: When Standard Tools Fail
After testing dozens of editors and online tools with files of increasing size, here's the practical breakdown:
| File Size | What Works | What Fails |
|---|---|---|
| < 1 MB | Everything - any editor, any online tool, any browser tab | Nothing fails at this size |
| 1–10 MB | VS Code, JetBrains IDEs, most online tools, jq | Notepad, basic text editors, some online formatters |
| 10–30 MB | VS Code (slow), jq, Python, specialized browser tools | Most online tools, Sublime (syntax highlighting) |
| 30–100 MB | jq, streaming parsers, Python ijson, DuckDB | VS Code freezes, all browser-based editors |
| 100–500 MB | Streaming parsers only, jq (with patience), DuckDB | Everything that loads the full file into memory |
| 500 MB+ | Streaming mandatory, consider format conversion | Even jq gets slow; rethink your approach |
The key insight: the threshold isn't about the tool's quality - it's about the fundamental approach. Any tool that loads the entire file into memory will hit a wall. The wall just moves depending on available RAM.
Technique 1: Streaming Parsers
Streaming (or SAX-style) parsing processes JSON token by token without building the entire object graph in memory. Instead of loading 200MB into a single data structure, you process one record at a time, keeping memory usage constant regardless of file size.
Node.js: stream-json
The stream-json package is my go-to for Node.js. It pipes JSON through a series of transforms, emitting objects one at a time:
// process-large-array.js
const { parser } = require('stream-json');
const { streamArray } = require('stream-json/streamers/StreamArray');
const { chain } = require('stream-chain');
const fs = require('fs');
let count = 0;
let errorCount = 0;
const pipeline = chain([
fs.createReadStream('events-500mb.json'),
parser(),
streamArray(),
]);
pipeline.on('data', ({ key, value }) => {
count++;
// Process each item individually memory stays flat
if (value.status === 'error') {
errorCount++;
}
if (count % 100000 === 0) {
console.log(
`Processed ${count} items, memory: ${(process.memoryUsage().heapUsed / 1024 / 1024).toFixed(0)} MB`
);
}
});
pipeline.on('end', () => {
console.log(`Done. ${count} total items, ${errorCount} errors.`);
});Real benchmark: Processing a 500MB JSON array (2.1 million objects) with this approach uses a constant ~80MB of memory and completes in 47 seconds on an M1 MacBook Pro. The same file with JSON.parse() requires 3.2GB of RAM and takes 31 seconds if it doesn't OOM first.
Python: ijson
Python's ijson provides the same streaming capability:
# process_large_json.py
import ijson
import sys
filename = sys.argv[1]
count = 0
active_users = 0
with open(filename, 'rb') as f:
# Parse items from a top-level array
for item in ijson.items(f, 'item'):
count += 1
if item.get('status') == 'active':
active_users += 1
if count % 100000 == 0:
print(f"Processed {count:,} items...")
print(f"Total: {count:,} items, {active_users:,} active users")Benchmark: The same 500MB file processes in 2 minutes 14 seconds with ijson (Python is slower than Node for this), but memory stays under 50MB throughout. Using json.load() would require 4GB+ and likely crash on a 16GB machine.
When to Use Streaming
- You need to process/filter/aggregate data from a large JSON array
- You don't need the entire object graph in memory simultaneously
- Memory is constrained (CI/CD runners, containers, serverless functions)
- The file is a top-level array (streaming works best with arrays)
When Streaming Doesn't Help
- You need random access to arbitrary paths in the document
- The file is a single deeply nested object (not an array)
- You need to reformat/pretty-print the entire file (you still need to write output)
Technique 2: Chunking and Pagination
Sometimes you don't need to process the entire file you just need to see part of it. Chunking splits a large JSON array into manageable pieces you can open in any tool.
Using jq to Extract Slices
jq is the Swiss Army knife for JSON on the command line. Extracting a slice from a large array:
# Get the first 100 items from a large array
jq '.[0:100]' massive-export.json > first-100.json
# Get items 500-600
jq '.[500:600]' massive-export.json > slice-500-600.json
# Get the last 50 items
jq '.[-50:]' massive-export.json > last-50.json
# Count total items without loading everything into an editor
jq 'length' massive-export.jsonA Bash Script for Splitting Large Arrays
When I need to split a 200MB export into reviewable chunks, I use this script:
#!/bin/bash
# split-json-array.sh - Split a large JSON array into chunks
# Usage: ./split-json-array.sh input.json 1000
INPUT_FILE="$1"
CHUNK_SIZE="${2:-1000}"
TOTAL=$(jq 'length' "$INPUT_FILE")
CHUNKS=$(( (TOTAL + CHUNK_SIZE - 1) / CHUNK_SIZE ))
echo "Total items: $TOTAL"
echo "Chunk size: $CHUNK_SIZE"
echo "Creating $CHUNKS chunks..."
for ((i=0; i<CHUNKS; i++)); do
START=$((i * CHUNK_SIZE))
OUTPUT="chunk_$(printf '%04d' $i).json"
jq ".[$START:$((START + CHUNK_SIZE))]" "$INPUT_FILE" > "$OUTPUT"
SIZE=$(wc -c < "$OUTPUT" | tr -d ' ')
echo " $OUTPUT — $SIZE bytes"
done
echo "Done. $CHUNKS files created."Real scenario: I used this last month to split a 150MB Mixpanel event export (890,000 events) into 890 files of 1,000 events each. Each chunk was ~170KB small enough to open in any editor, grep through, or paste into an online formatter for inspection.
Python Chunking for Non-Array JSON
When the large file isn't a simple array (e.g., it's an object with many top-level keys), Python handles it well:
# chunk_json_object.py - Split a large JSON object by top-level keys
import json
import sys
import os
input_file = sys.argv[1]
keys_per_chunk = int(sys.argv[2]) if len(sys.argv) > 2 else 50
with open(input_file, 'r') as f:
data = json.load(f)
keys = list(data.keys())
total_chunks = (len(keys) + keys_per_chunk - 1) // keys_per_chunk
for i in range(total_chunks):
chunk_keys = keys[i * keys_per_chunk:(i + 1) * keys_per_chunk]
chunk = {k: data[k] for k in chunk_keys}
output = f"chunk_{i:04d}.json"
with open(output, 'w') as f:
json.dump(chunk, f, indent=2)
print(f" {output} — {len(chunk_keys)} keys, {os.path.getsize(output)} bytes")Technique 3: Command-Line Formatting
When your editor can't handle the file, the command line almost always can. CLI tools process files as streams and don't need to render anything they just read, transform, and write.
jq - The Gold Standard
# Pretty-print a large file (streaming output, constant memory for formatting)
jq '.' raw-export.json > formatted.json
# Compact/minify (reduces file size significantly)
jq -c '.' formatted.json > minified.json
# Format with specific indentation (jq uses 2 spaces by default)
jq --indent 4 '.' data.json > data-4space.jsonPython's Built-in json.tool
No installation required it ships with Python:
# Format with Python (available on virtually every system)
python3 -m json.tool raw-export.json > formatted.json
# With custom indentation
python3 -c "
import json, sys
data = json.load(open(sys.argv[1]))
json.dump(data, open(sys.argv[2], 'w'), indent=4)
" raw-export.json formatted.jsonNode.js 22 One-Liner
# Using Node.js 22 LTS (useful if you're already in a JS project)
node -e "
const fs = require('fs');
const data = JSON.parse(fs.readFileSync(process.argv[1], 'utf8'));
fs.writeFileSync(process.argv[2], JSON.stringify(data, null, 2));
" raw-export.json formatted.jsonPerformance Comparison: CLI Formatters
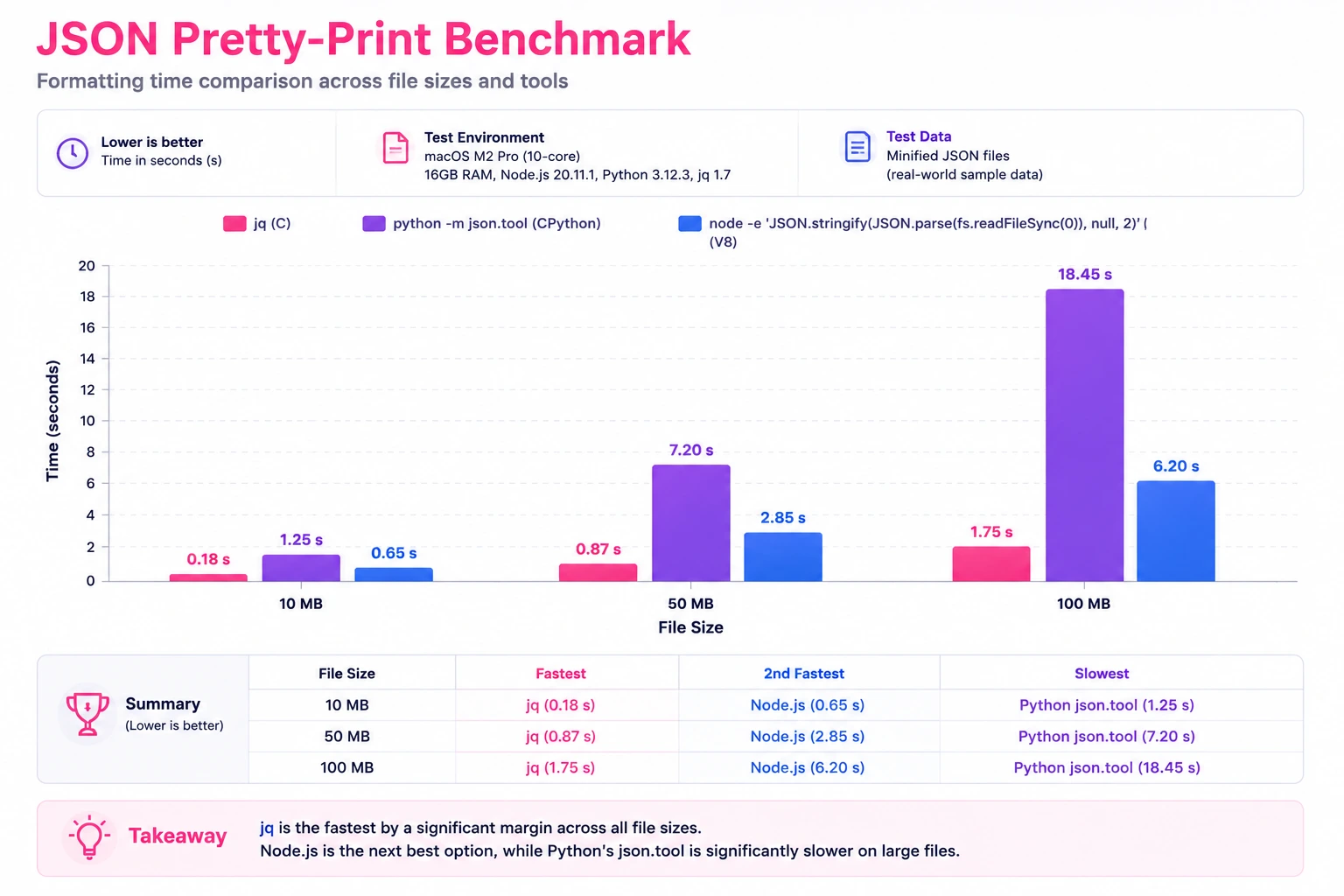
I benchmarked these three approaches on the same files (M1 MacBook Pro, 16GB RAM, SSD, Node 22 LTS):
| File Size | jq . | python3 -m json.tool | node (JSON.stringify) | Notes |
|---|---|---|---|---|
| 10 MB | 0.8s | 1.2s | 0.6s | All fast, negligible difference |
| 50 MB | 3.9s | 6.1s | 3.2s | Node 22 wins on raw parse/stringify speed |
| 100 MB | 8.2s | 13.4s | 7.1s | Node 22 still fastest but uses 650MB RAM |
| 200 MB | 17.8s | 28.6s | OOM (default) | Node needs --max-old-space-size=4096 |
| 500 MB | 52s | 74s | 41s (4GB heap) | jq is most memory-efficient throughout |
Key takeaway: jq is the most reliable choice because it handles memory efficiently at all sizes. Node.js 22 is fastest for files under 100MB but needs manual heap configuration for larger files. Python is slowest but never crashes it just takes longer.
Technique 4: Browser-Based Tools That Actually Handle Large Files
Not every situation allows CLI access. Maybe you're on a locked-down corporate machine, debugging from a colleague's laptop, or simply prefer a visual interface. The question is: which browser-based tools can handle files beyond the typical 1-2MB limit?
What Makes a Browser Tool Handle Large JSON
The difference between a tool that crashes at 5MB and one that handles 30MB comes down to architecture:
- Web Workers: Parsing and formatting happen off the main thread. The UI stays responsive while a background thread does the heavy lifting.
- Virtual scrolling: Instead of rendering 500,000 lines in the DOM, only the ~50 visible lines are rendered. As you scroll, elements are recycled.
- Incremental parsing: The file is parsed in chunks, with progress feedback, rather than a single blocking
JSON.parse()call. - Memory-conscious rendering: Collapsed tree nodes don't allocate DOM elements until expanded.
Practical Limits of Browser-Based Formatting
Even with these optimizations, browsers have hard limits:
- V8 string size limit: ~512MB for a single string (the raw JSON text)
- Tab memory limit: Chrome kills tabs that exceed ~4GB (varies by OS)
- Web Worker transfer: Passing large strings to Workers via
postMessageinvolves serialization overhead
In practice, well-built browser tools handle files up to 30MB comfortably. Beyond that, you're fighting the browser's architecture.
OnlineJSONFormatt uses Web Workers and WASM-compiled processing to handle JSON files up to 30MB in the browser which covers the vast majority of "my editor crashed" scenarios. For files beyond that threshold, the CLI techniques above are the right approach.
Large JSON in 3D/Three.js Applications
If you work with Three.js or WebGL, you've likely hit a wall that most web developers never encounter: a single .json model file consuming 800MB-1.5GB of browser memory before a single triangle renders on screen.
Three.js scenes export geometry, materials, animations, and morph targets as JSON (the .json model format and glTF's .gltf variant). A photogrammetry scan or CAD export can easily produce a 200MB+ JSON geometry file and once Three.js parses it with JSON.parse(), memory amplification kicks in exactly as described above. A 200MB model file can balloon to 1.2–1.5GB in heap, leaving almost nothing for textures, physics, or the rest of your application.
The Memory Budget Problem
Browser tabs on desktop typically get 4GB max. On mobile, it's closer to 1–2GB. Here's what a real Three.js scene memory budget looks like:
| Component | Typical Usage |
|---|---|
| Three.js core + renderer | 50–100 MB |
| Textures (compressed) | 200–500 MB |
| Geometry buffers (GPU) | 100–400 MB |
| JSON model parse overhead | 600–1,500 MB |
| Audio, physics, UI | 50–150 MB |
The JSON parse step is often the single largest memory consumer and it's temporary. Once geometry is transferred to GPU buffers, the parsed JSON object graph is garbage. But the GC can't reclaim it fast enough if you've already hit the tab memory ceiling.
Strategies That Actually Work
1. Use glTF Binary (.glb) instead of JSON
The single most impactful change. glTF Binary stores geometry as raw typed arrays no JSON parsing overhead, no memory amplification:
// Instead of loading a 200MB .json model:
// const loader = new THREE.ObjectLoader();
// loader.load('scene.json', ...); // 1.2GB memory spike
// Use glTF Binary — same geometry, ~60% smaller file, no parse spike
import { GLTFLoader } from 'three/addons/loaders/GLTFLoader.js';
const loader = new GLTFLoader();
loader.load('scene.glb', (gltf) => {
scene.add(gltf.scene);
// Memory used: ~400MB (geometry buffers only, no JSON overhead)
});2. Stream large geometry with progressive loading
For scenes that must stay in JSON format (legacy pipelines, procedural geometry), load geometry in chunks:
// progressive-geometry-loader.js
async function loadLargeGeometry(url, onChunk) {
const response = await fetch(url);
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
let vertexCount = 0;
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
// Process complete vertex batches as they arrive
const batches = extractCompleteBatches(buffer);
for (const batch of batches) {
onChunk(batch);
vertexCount += batch.length / 3;
console.log(`Loaded ${vertexCount.toLocaleString()} vertices, heap: ${(performance.memory?.usedJSHeapSize / 1024 / 1024).toFixed(0)}MB`);
}
}
}3. Draco compression for JSON geometry data
If your pipeline exports JSON with raw vertex arrays, compress the geometry with Draco before serving:
# Convert JSON geometry to compressed glTF with Draco
npx gltf-pipeline -i model.gltf -o model-draco.glb --draco.compressionLevel 7
# Typical results:
# model.json: 180 MB (raw JSON geometry)
# model.glb: 72 MB (binary, no compression)
# model-draco.glb: 14 MB (Draco compressed) — 92% smaller than JSON4. Validate and repair large model JSON before loading
Corrupted JSON model files are common when exporting from Blender or Maya especially with large vertex counts where exporters hit buffer limits. Use our JSON fixer to validate model files before loading them into Three.js, or pipe through jq to verify structure:
# Quick structure check on a large Three.js JSON model
jq '.geometries | length' scene.json
# → 847 (number of geometry objects)
jq '.geometries[0].data.attributes.position.array | length' scene.json
# → 2847291 (vertex count × 3 for the first geometry)Real-World Impact
Last quarter I helped a team optimize a architectural visualization app. Their main scene file was a 340MB JSON export from Revit → Blender → Three.js ObjectLoader. Browser memory peaked at 2.1GB during load, causing crashes on 8GB laptops.
After converting to glTF Binary with Draco compression: file size dropped to 28MB, memory peak during load fell to 380MB, and initial render time went from 12 seconds to 1.8 seconds. Same geometry, same visual quality just a better format for the data.
Technique 5: Converting to a Better Format
Sometimes the real answer isn't "how do I format this large JSON file" it's "should this data be JSON at all?" When files consistently exceed 100MB, JSON's verbosity becomes a liability. Here are formats better suited for large datasets.
NDJSON (Newline-Delimited JSON)
NDJSON puts one JSON object per line, with no wrapping array. This makes it inherently streamable you can process it with standard Unix tools:
# Convert a JSON array to NDJSON
jq -c '.[]' large-array.json > output.ndjson
# Process NDJSON line by line (constant memory)
while IFS= read -r line; do
echo "$line" | jq '.userId'
done < output.ndjson
# Count lines (items) instantly
wc -l output.ndjson
# Filter with grep (faster than jq for simple matches)
grep '"status":"error"' output.ndjson | wc -l
# Take the first 100 records
head -100 output.ndjsonWhy NDJSON wins for large datasets: A 500MB JSON array requires parsing the entire file to access any element. The same data as NDJSON lets you head, tail, grep, and wc with zero parsing overhead. Every Unix tool becomes a JSON tool.
Parquet: When You Need Columnar Access
For analytical workloads filtering, aggregating, selecting specific columns from millions of rows Parquet is dramatically more efficient than JSON:
# convert_json_to_parquet.py
import pandas as pd
import sys
input_file = sys.argv[1]
output_file = input_file.replace('.json', '.parquet')
# Read JSON (this still loads into memory - use for files < available RAM)
df = pd.read_json(input_file)
# Write as Parquet with compression
df.to_parquet(output_file, compression='snappy', index=False)
original_size = os.path.getsize(input_file) / 1024 / 1024
parquet_size = os.path.getsize(output_file) / 1024 / 1024
print(f"JSON: {original_size:.1f} MB → Parquet: {parquet_size:.1f} MB ({(1 - parquet_size/original_size)*100:.0f}% smaller)")Real numbers: A 200MB JSON file with analytics events (flat structure, many repeated string values) compresses to 18MB as Parquet with Snappy compression a 91% reduction. And querying specific columns from Parquet doesn't require reading the entire file.
DuckDB: SQL on JSON Without Conversion
DuckDB can query JSON files directly with SQL, using streaming reads:
# Query a large JSON file with SQL - no conversion needed
duckdb -c "
SELECT status, COUNT(*) as count
FROM read_json_auto('events-500mb.json')
GROUP BY status
ORDER BY count DESC
"
# Export filtered results as formatted JSON
duckdb -c "
COPY (
SELECT * FROM read_json_auto('events-500mb.json')
WHERE created_at > '2024-01-01'
AND status = 'active'
) TO 'filtered.json' (FORMAT JSON, ARRAY true)
"DuckDB handles files larger than available RAM by spilling to disk. It's my preferred approach when I need to explore a large JSON file without committing to a full conversion pipeline.
My Workflow: A Decision Tree for Large JSON Files
After years of dealing with oversized JSON, here's the decision process I follow:
Step 1: How big is the file?
- Under 10MB → Open in VS Code or paste into a browser-based formatter. Done.
- 10–30MB → Use a browser tool with Web Worker support, or
jqif I need speed. - 30–100MB → CLI only.
jq .for formatting,jq 'expression'for filtering. - Over 100MB → Streaming parser or DuckDB. Consider converting to NDJSON/Parquet.
Step 2: What do I actually need?
- Just see the structure →
jq '.' | head -100or extract a small slice withjq '.[0:10]' - Find specific records →
jq 'map(select(.status == "error"))'or DuckDB SQL query - Format the whole file →
jq '.' input.json > formatted.json(let it run) - Aggregate/analyze → DuckDB every time. SQL is faster to write than jq expressions for complex queries.
- Share with non-technical people → Convert to CSV/Parquet, or chunk into small files they can open in Excel.
Step 3: Is this a recurring task?
- One-time exploration → CLI tools, quick and disposable
- Regular pipeline → Write a proper script with streaming, add it to your toolchain
- Team workflow → Convert to a queryable format (Parquet + DuckDB, or load into a database)
Common Mistakes I See (and Made Myself)
- Opening the file in an editor "just to check" - This is how you lose 5 minutes waiting for a crash. Always check file size first:
ls -lh file.jsonorwc -c file.json. - Using
JSON.parse()on files over 50MB without increasing heap - Node.js 22 defaults to ~4GB heap on 64-bit systems, but constrained environments (containers, CI runners) often set lower limits. Always set `--max-old-space-size` explicitly for large files. - Piping
curloutput directly intojqfor large responses - If the API returns 200MB,jqbuffers the entire response before processing. Usecurl -o file.jsonfirst, then process the file. - Assuming "streaming" means "fast" - Streaming is about memory efficiency, not speed. Processing 500MB streaming takes longer than
JSON.parse()on the same file (if you have enough RAM). The tradeoff is: streaming never crashes. - Not considering whether JSON is the right format - If you're regularly working with files over 100MB, the data probably belongs in a database, a Parquet file, or at minimum NDJSON. JSON arrays weren't designed for datasets with millions of rows.
Conclusion
Large JSON files aren't going away. APIs return bigger payloads, logging systems export more data, and database dumps keep growing. The key is matching your tool to the file size:
- Under 30MB: Browser-based tools and editors handle this fine with the right architecture (Web Workers, virtual scrolling).
- 30–100MB: Command-line tools like
jqare your best friend. Fast, memory-efficient, scriptable. - Over 100MB: Streaming parsers for processing, DuckDB for querying, and format conversion (NDJSON/Parquet) for long-term sanity.
The techniques in this guide have saved me countless hours of waiting for frozen editors and crashed browser tabs. The 30 seconds it takes to check file size and choose the right approach pays for itself every single time.